Olin College of Engineering
Independent
University of Texas at Dallas
University of Oxford
University College London
Independent
ShanghaiTech University
Columbia University
University of Manchester
*Equal contribution. Correspondence to acostarelli@olin.edu.
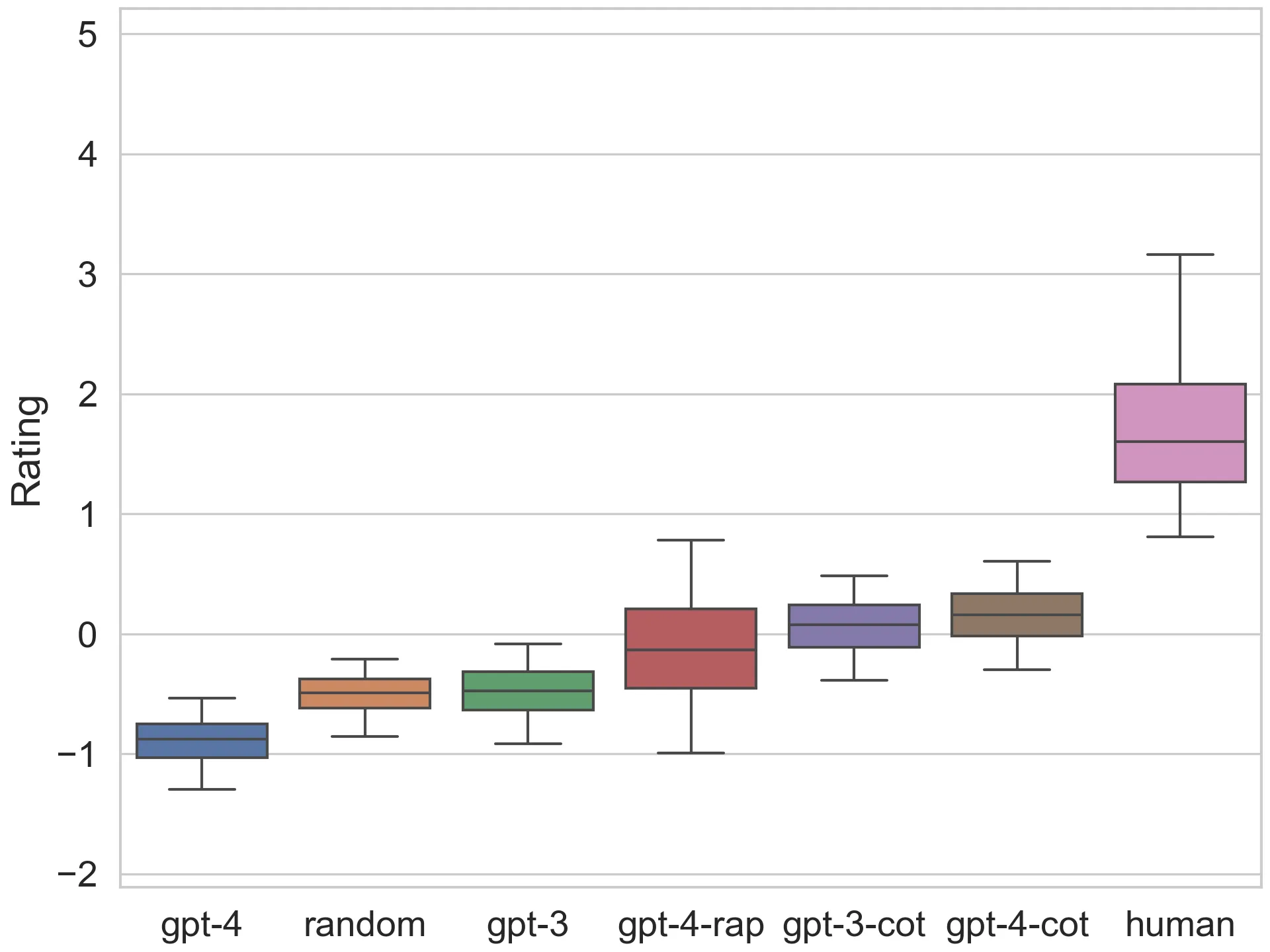
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents’ performance across various types of reasoning found in games. To address this gap, we introduce GAMEBENCH, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models’ pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP).
With CoT scaffolding, GPT-4 is the best reasoner below only the human baseline, achieving the best performance on Sea Battle and Pit. But without scaffolding, it performs worse than even the random baseline due to its exceedingly low rating on Sea Battle. The state-of-the-art RAP scaffolding doesn’t provide as much of an improvement to GPT-4 as CoT does.
@misc{costarelli2024gamebench,
title={GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents},
author={Anthony Costarelli and Mat Allen and Roman Hauksson and Grace Sodunke and Suhas Hariharan and Carlson Cheng and Wenjie Li and Joshua Clymer and Arjun Yadav},
year={2024},
eprint={2406.06613},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}